
Kafka 카프카 활용 아키텍쳐 사례 분석
Kafka Architecture
플랫폼화 되어있는 아키텍쳐같은 경우에는 공부하고 사례검토를 한후 진행하는것이 좋다.
우선적으로 기술적인 측면을 으로 고려하기 보다는 타 회사에서 어떤 니즈를 위해 어떤 아키텍쳐를 구성했는지 파악해보자.
1. 카카오 스마트 메세지 서비스
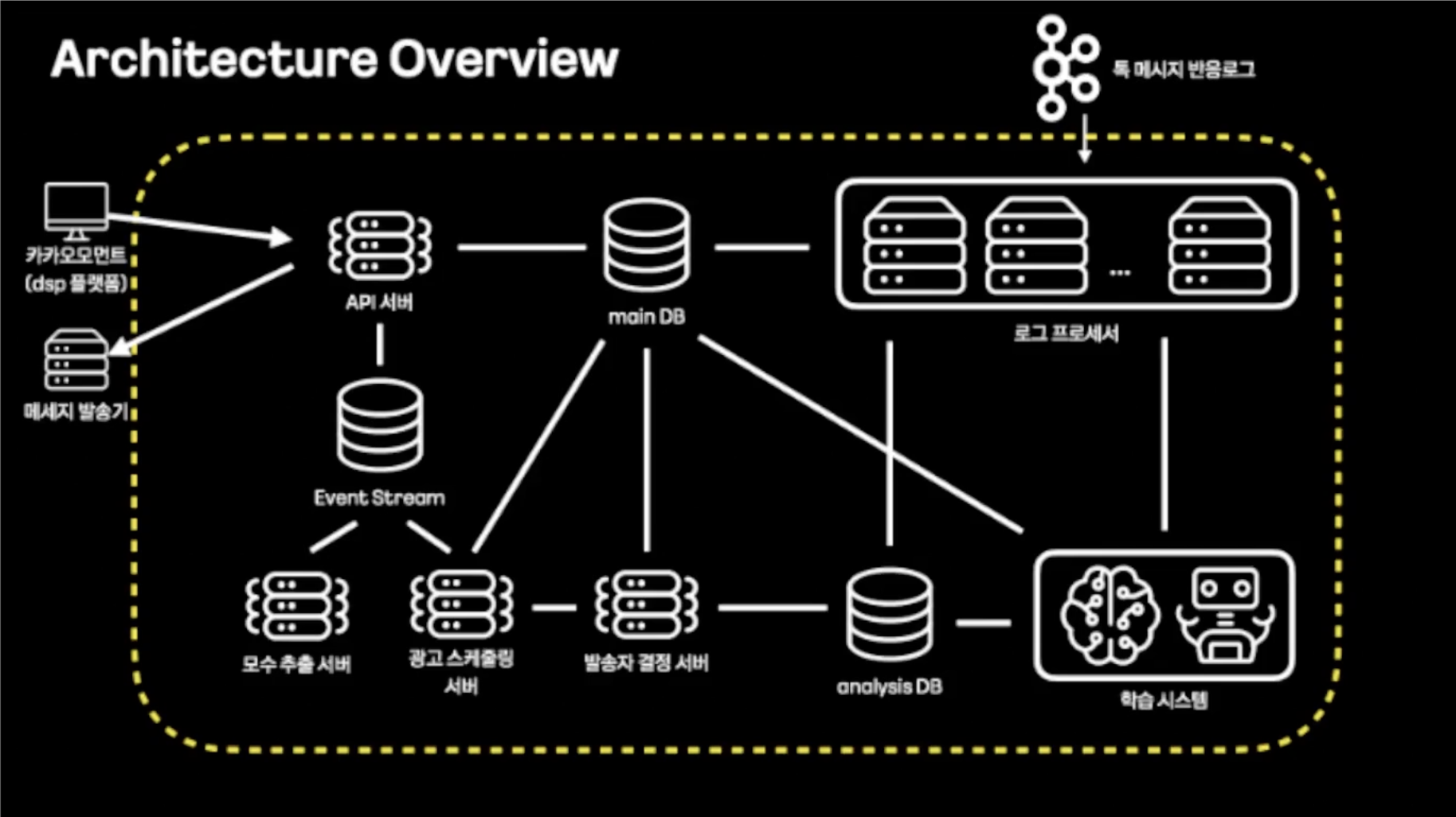
스마트 메세지 서비스는 소재 최적화와 유저 타켓팅을 통해 적합한 유저에게 광고 메세지를 개인화 전송하는 서비스이다. 사용자에게 흥미가 있는 소재를 최적화하고 적합한 유저에게 타겟팅하여 광고를 선별 전송한다.
https://if.kakao.com/session/22
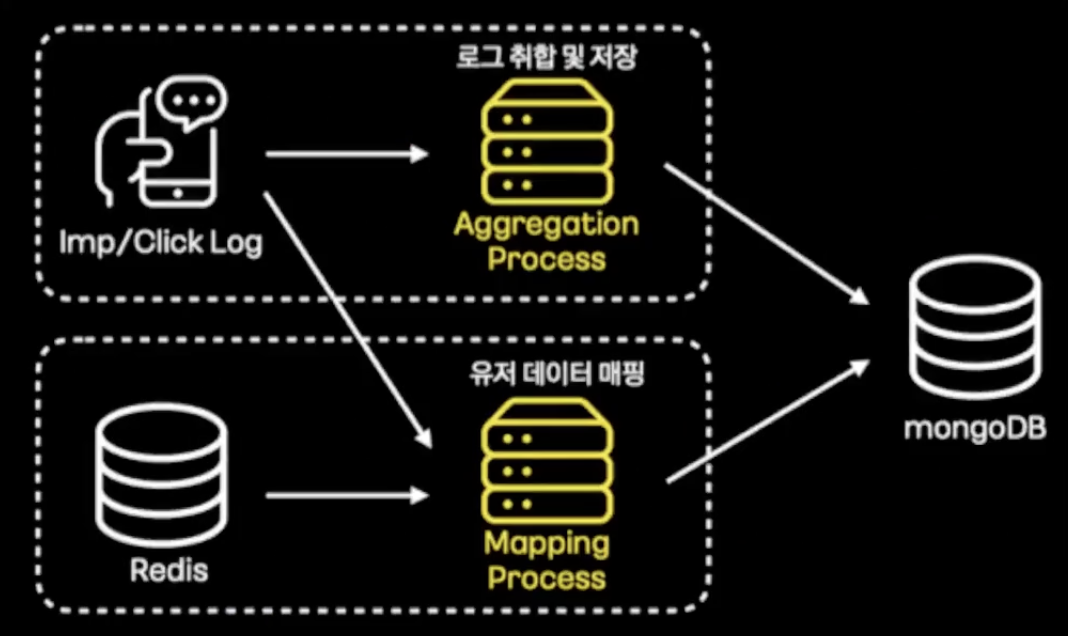
사용자의 반응 로그(imp, click)을 취합하여 저장하고 유저 데이터를 매핑하여 처리하는 용도로 카프카 스트림즈를 활용했다. - 몽고디비에 부하를 줄이기 위해 취합 저장 - 많은 양의 데이터를 안정적으로 저장
카프카 스트림즈의 groupByKey, windowedBy, aggregate 구문을 통해 1분 로그를 window 취합하여 적잭하고, map 구문을 통해 Redis의 유저데이터와 결합 처리하는 로직을 수행한다.
2. 넷플릭스 키스톤 프로젝트
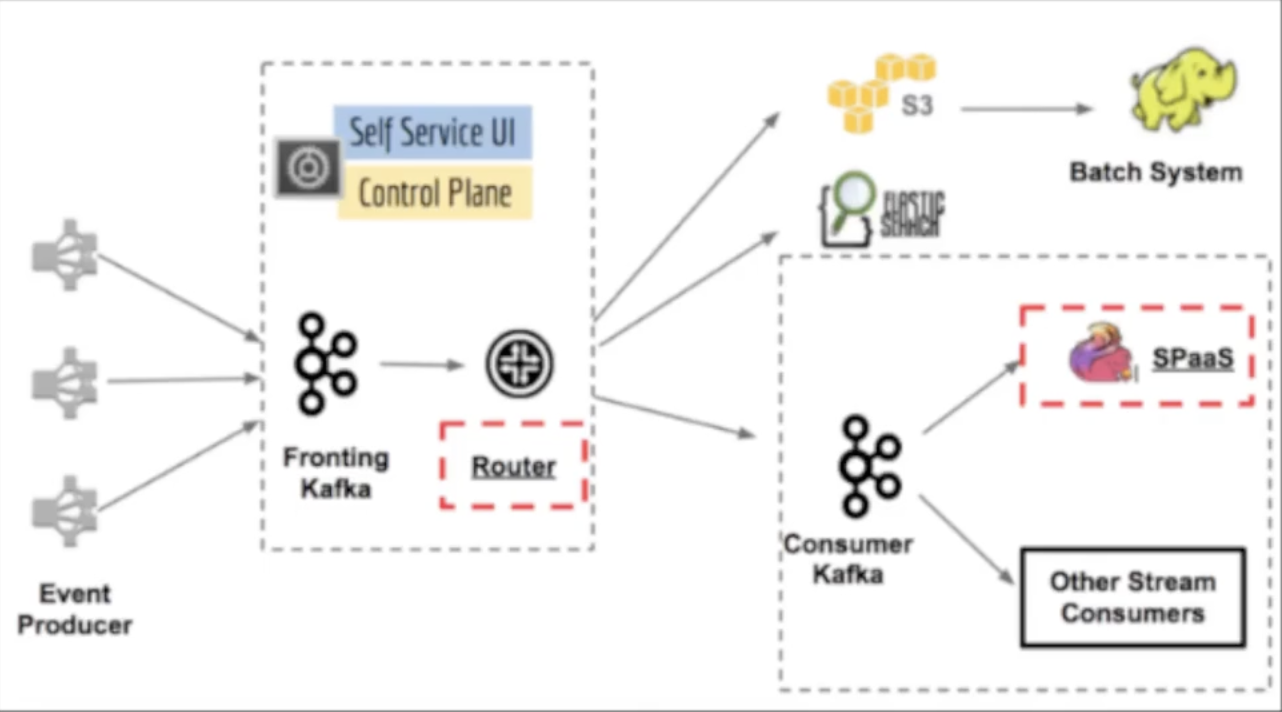
https://netflixtechblog.com/keystone-real-time-stream-processing-platform-a3ee651812a
-
첫번째 단계 카프카는 라우팅 용도로 모든 데이터를 수집
-
Router(자체 스트림 프로세싱, 라우팅 애플리케이션)을 사용하여 두번째 카프카 또는 하둡, 엘라스틱서치와 같은 데이터베이스로 전달
3. 라인 쇼핑 플랫폼 사례
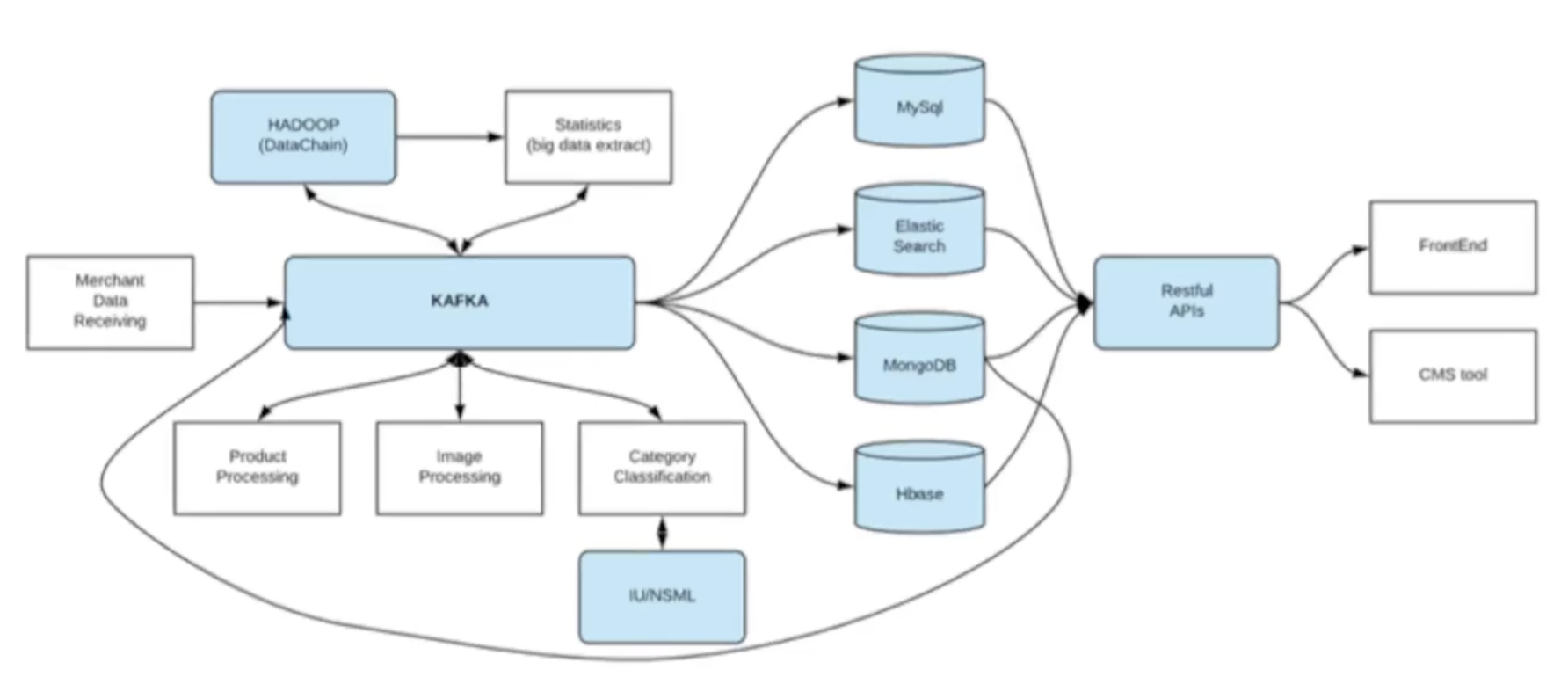
https://engineering.linecorp.com/ko/blog/line-shopping-platform-kafka-mongodb-kubernetes
-
시스템 유연성을 개선하고 처리량의 한계를 없애기 위해 카프카를 중앙에 둔 아키텍쳐 적용
-
카프카 커넥트 도입. mongodb CDC(Change Data Capture) 커넥터 활용
-
이벤트 기반 데이터 처리로 상품 처리가 매우 빨라짐
4. 11번가, 주문/결제 시스템 적용 사례
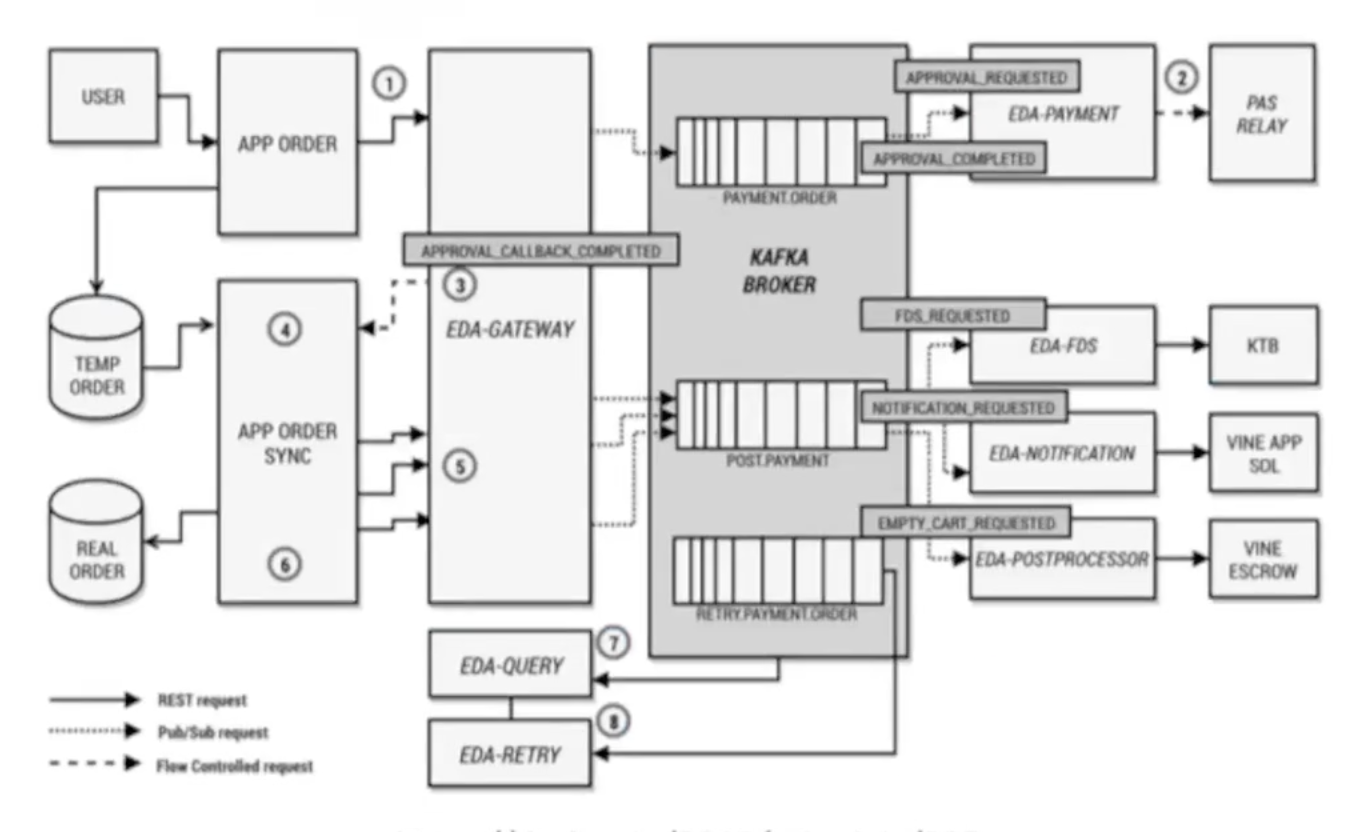
https://deview.kr/2019/schedule/305
-
데이터베이스의 병목현상을 해소하기 위해 도입
-
카프카 단일 진실 공급원(Source of Truth)으로 정의
-
메세지를 Materalized View로 구축하여 배치 데이터처럼 활용
카프카 기술 별 아키텍쳐 적용 방법 정리
- 카프카 커넥트
- 반복적인 파이프라인을 만들어야할 경우 분산 모드 커넥트를 설치하고 운영
- 되도록 오픈소스 커넥터를 사용하되, 필요시 커스텀 커텍터를 개발하여 운영
- rest api와 통신하여 동작할 수 있는 웹 화면을 개발하거나 오픈소스 활용를 추천
- 카프카 스트림즈
- 강력한 stateful, stateless 프로세싱 기능이 들어있으므로 카프카의 토픽의 데이터 처리시 선택
- 카프카 컨슈머, 프로듀서
- 커넥트와 스트림즈로 구현할 수 없거나 단일성 파이프라인, 개발일 경우에는 컨슈머 또는 프로듀서로 개발
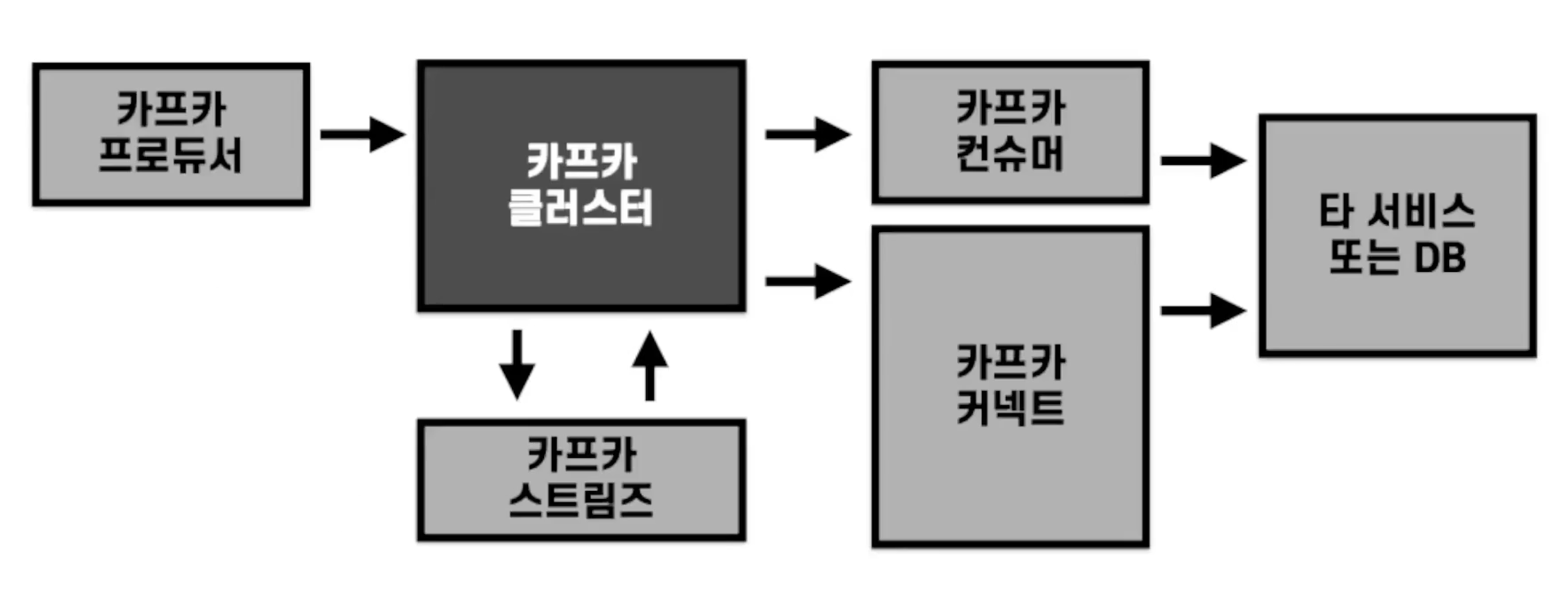
-
프로듀서를 통해 최초로 데이터 유입
-
토픽 기반 데이터 프로세싱은 카프카 스트림즈로 처리
-
반복되는 파이프라인은 카프카 커넥트에서 운영. 단발적인 처리는 컨슈머로 개발
Comments