
Kafka 카프카 분산 모드 커넥트
Kafka Distributed Mode Connect
분산 모드 커넥트는 단일 모드 커넥트와 다르개 2개 이상의 프로세스가 1개의 그룹으로 묶여서 운영된다.
이를 통해 1개의 커넥트 프로세스에 이슈가 발생하여 종료되더라도 살아있는 나머지 1개 커넥트 프로세스가 커넥터를 이어받아서 파이프라인을 지속적으로 실행할 수 있다는 특징이 있다.
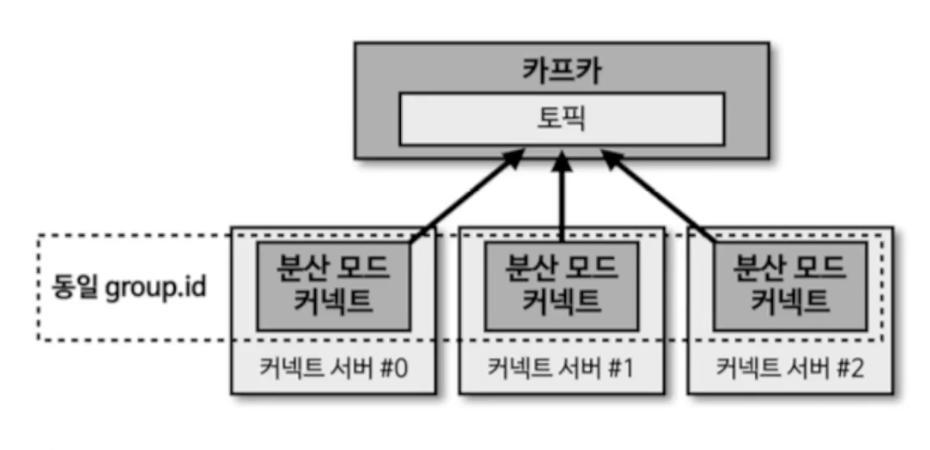
분산 모드 설정
분산 모드 설정 파일 : 카프카 바이너리 디렉토리/config/connect-distributed.properties
- connect-distributed.properties
bootstrap.servers=my-kafka:9092key.converter=org.apache.kafka.connect.json.JsonConvertervalue.converter=org.apache.kafka.connect.json.JsonConverterkey.converter.schemas.enable=falsevalue.converter.schemas.enable=falseoffset.storage.topic=connect-offsets- 분산 모드에서 데이터 및 설정을 위한 토픽정보이다. 실행하기 전에 토픽을 미리 생성해 두어야 한다. 해당 토픽 데이터 정합성에 문제가 생기면 커넥트의 설정이 꼬여버릴 수 있기 때문에 주의해야한다. (아래 2종류 옵션도 동일)
offset.storage.replication.factor=1config.storage.topic=connect-configsconfig.storage.replication.factor=1status.storage.topic=connect-statusstatus.storage.replication.factor=1offset.flush.interval.ms=10000plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins
Comments