
Kafka 카프카 커넥트
Kafka Connect
카프카 커넥트(kafka connect)는 카프카 오픈소스에 포함된 툴 중 하나로 데이터 파이프라인 생성 시 반복 작업을 줄이고 효율적인 전송을 이루기 위한 애플리케이션이다.
커넥트는 특정한 작업 형태를 템플릿으로 만들어놓은 커넥터(connector)를 실행함으로써 반복 작업을 줄일 수 있다.
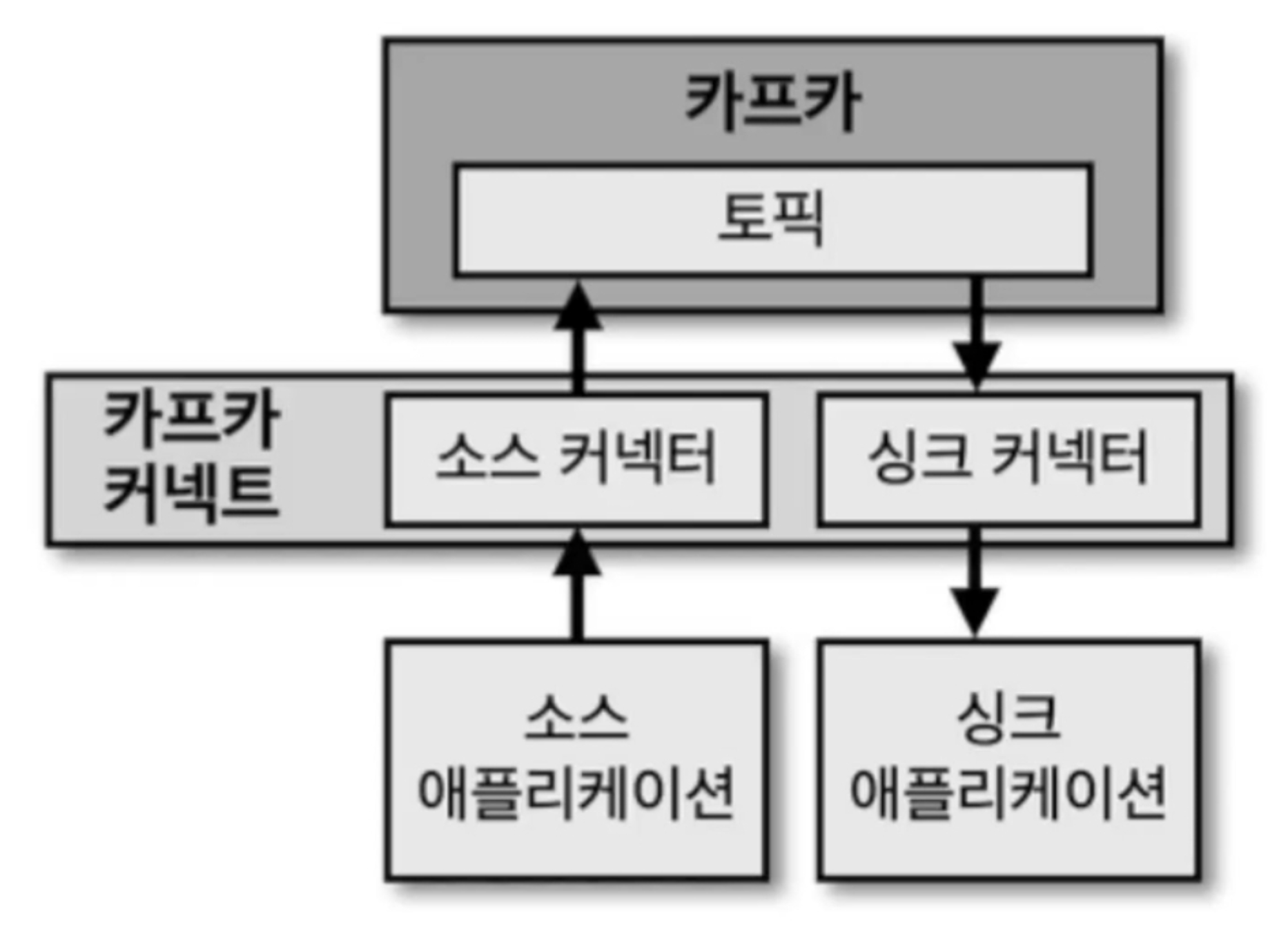
커넥트 내부 구조
- 사용자가 커넥트에 커넥터 생성 명령을 내리면 커넥트는 내부에 커넥터와 태스크를 생성한다.
- 커넥터는 태스크들을 관리한다. (오케스트레이션)
- 태스크는 커넥터에 종속되는 개념으로 실질적인 데이터 처리를 한다.
- 그렇기 때문에 데이터 처리를 정상적으로 하는지 확인하기 위해서는 각 태스크의 상태를 확인해야 한다.

소스 커넥터, 싱크 커넥터
커넥터는 프로듀서 역할을 하는 ‘소스 커넥터(source connector)’와 컨슈머 역할을 하는 ‘싱크 커넥터(sink connector)’ 2가지로 나뉜다.
예를 들어, 파일을 주고받는 용도로 파일 소스 커넥터(file source connector)와 파일 싱크 커넥터(sink connector)가 있다고 가정하자. 파일 소스 커넥터는 파일의 데이터를 카프카 토픽으로 전송하는 프로듀서 역할을 한다. 그리고 파일 싱크 커넥터는 토픽의 데이터를 파일로 저장하는 컨슈머 역할을 한다. 파일 외에도 일정한 프로토콜을 가진 소스 애플리케이션이나 싱크 애플리케이션이 있다면 커넥터를 통해 카프카로 데이터를 보내거나 카프카에서 데이터를 가져올 수 있다.
MySQL, S3, MongoDB 등과 같은 저장소를 대표적인 싱크 애플리케이션, 소스 애플리케이션이라 볼 수 있다.
즉, MySQL에서 카프카로 데이터를 보낼 때 그리고 카프카에서 데이터를 MySQL로 저장할 때 JDBC 커넥터를 사용하여 파이프라인을 사용할 수 있다.
커넥터 플러그인
카프카 2.6에 포함된 커넥트를 실행할 경우 클러스터 간 토픽 미러링을 지원하는 미러메이커2 커넥터와 파일 싱크 커넥터, 파일 소스 커넥터를 기본 플러그인으로 제공한다.
- 이외에 추가적인 커넥터를 사용하고 싶다면 플러그인 형태로 커넥터 jar파일을 추가하여 사용할 수 있다.
- 커넥터 jar파일에는 커텍터를 구현하는 클래스를 빌드한 클래스 파일이 포함되어 있다.
- 커넥터 플러그인을 추가하고 싶다면 직접 커넥터 플러그인을 만들거나 이미 인터넷상에 존재하는 플러그인을 가져다 쓸 수도 있다
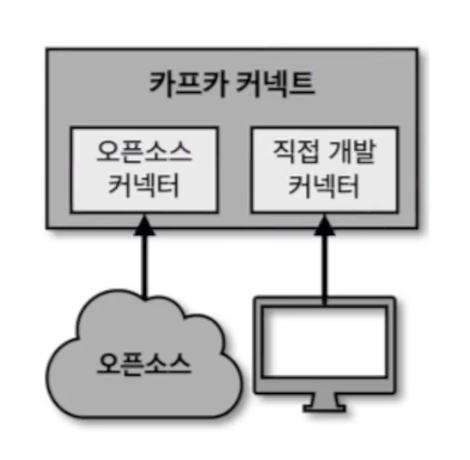
오픈소스 커넥터
오픈소스 커넥터는 직접 커넥터를 만들 필요가 없으며 커넥터 jar파일을 다운로드하여 사용할 수 있다는 장점이 있다. HDFS 커넥터, AWS S3 커넥터, JDBC 커넥터, 엘라스틱서치 커넥터 등 100개가 넘는 커넥터들이 이미 공개되어 있다. 필요한 커넥터를 검색하고 아키텍쳐에 알맞은 커넥터를 찾아서 다운받아 사용하면 된다.
오픈소스 커넥터의 종류는 컨플루언트 허브(https://www.confluent.io/hub/) 에서 검색할 수 있다.
다만, 오픈소스라고 모두 무료로 제한없이 사용할 수 있는 것은 아니기 때문에 라이센스를 참고하여 사용범위를 확인한 이후에 사용해야 한다.
컨버터, 트랜스폼
사용자가 커넥터를 사용하여 파이프라인을 생성할 때 컨버터(converter)와 트랜스폼(transform) 기능을 옵션으로 추가할 수 있다. 커넥터를 운영할 때 반드시 필요한 설정은 아니지만 데이터 처리를 더욱 풍부하게 도와주는 역할을 한다.
컨버터는 데이터 처리를 하기 전에 스키마를 변경하도록 도와준다. JsonConverter, String Converter, ByteArrayConverter를 지원하고 필요하다면 커스텀 컨버터를 작성하여 사용할 수도 있다.
트랜스폼은 데이터 처리 시 각 메세지 단위로 데이터를 간단하게 변환하기 위한 용도로 사용된다. 예를 들어, JSON 데이터를 커넥터에서 사용할 때 트랜스폼을 사용하면 특정 키를 삭제하거나 추가할 수 있다. 기본 제공 트랜스폼으로 Cast, Drop, ExtractField 등이 있다.
Comments